딥러닝 홀로서기 프로젝트_Lec2_ML Basic
https://youtu.be/hPXeVHdIdmw?si=GeueKf4G_J-9Di32
Deep Learning, Machine Learning, Artifcial Intelligence : 딥러닝, 머신러닝, AI의 구분 (범위 차이)
Artifical Intelligence > Machine Learning > Representation Learning > Deep Learning
- 룰 베이스*로 모든 것을 짜더라도 겉으로 보기에 알아서 처리하는 것처럼 보이면 AI(Artificial Intelligence)라고 이야기할 수 있기에 포함 관계에서 가장 큰 범위를 가진다.
- Deep Learning : ML의 성능을 높인 것으로, Feature Extractor라고 할 수 있다.
- DL은 가장 작은 포함관계에 있음을 알 수 있다.
* 룰 베이스 : if문 등의 모든 상황에 대하여 규칙을 가지는 코드

Categories of ML Problem : ML의 카테고리
ML은 다음과 같이 네 가지로 구분할 수 있다.
가로는 학습법에 따른 분류를 나타내며, 세로는 이산형(Discrete)과 Continuous(연속형)이라는 output space에 따른 분류를 나타낸다.

가로 : 학습 법에 따른 분류 / 세로 : output space에 따른 분류
- Supervised Learning : 정해진 label을 맞추도록 학습하는 방법.
>> ex) 주어진 사진이 강아지인지, 고양이인지 맞춘다.
- Unsupervised Learning : 정해지지 않은 label을 구분하도록 학습하는 방법. (ex. Clustering 군집화)
>> ex) 사용자의 플레이 리스트에서 선호하는 음악을 분류한다.
- Semi-Supervised Learning : 정해진 label을 맞추도록 학습한 뒤, 그 사잇값을 짐작하여 주어진 데이터를 맞추게 하는 방법.
>> ex) 주식의 변화를 보고 다음을 예측한다.
- Reinforcement Learning : 환경과 자신의 상태가 함께 input으로 들어갔을 때 상태의 변화를 측정하는 학습법.
>> ex) 자율 주행 자동차가 빨간 불에 신호를 지났을 때 '나쁨' 상태를 받는다. 초록 불에 신호를 지났을 때에는 '좋음' 상태를 받는다. 그러면 '좋음' 상태에 맞추기 위해 다양한 상황을 고려하여 자율 주행을 조정한다.
Supervised Learning
- Regression Problem [ Continuous ]
목적 : 다음 상황에 대한 예측
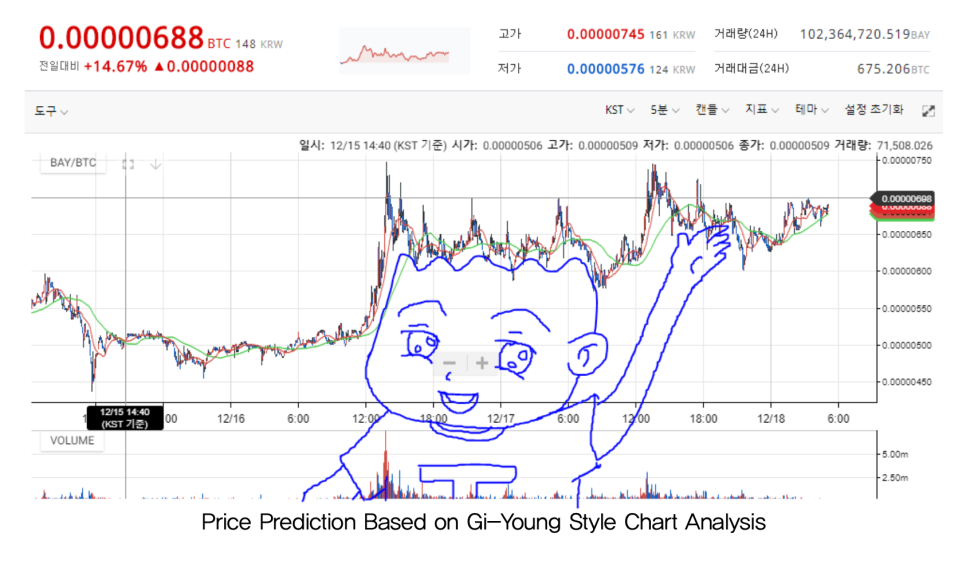
[ 예시 1 ] : 주가 예측 프로그램
다음 그림은 주식 예측에 대한 자료를 보여주고 있다.
12/16 00:00 부터 12/17 12:00 까지의 데이터를 입력 받아, 12/17 12:00 부터 12/18 06:00 까지의 값을 예측한 모습이다.
언제 주식이 오르고 내릴지 간단하게 예측이 가능하다.
[ 예시 2 ] : 평균 변화량을 학습하여 적절한 변화 그래프 추출
아래의 그림은 함수의 형태를 나타내고 있다.
함수 f(x)는 x를 입력값으로 가지며, x를 y로 만들기 위한 함수이다.
이 함수의 목적은 x값을 얼마나 잘 y값으로 치환하는가에 있으며, 연속적인 값을 가지는 것이 특징이다.
죄측 그래프는 각 x에 대하여 y가 어떤 값을 가지는지 확인한 후, 직선 기울기(Linear Regression)*에 반영하고 있다.
이와 마찬가지로 우측 그래프 또한 기울기 변화를 곡선 기울기(Nonelinear Regression)*로 반영하는 모습을 확인할 수 있다.
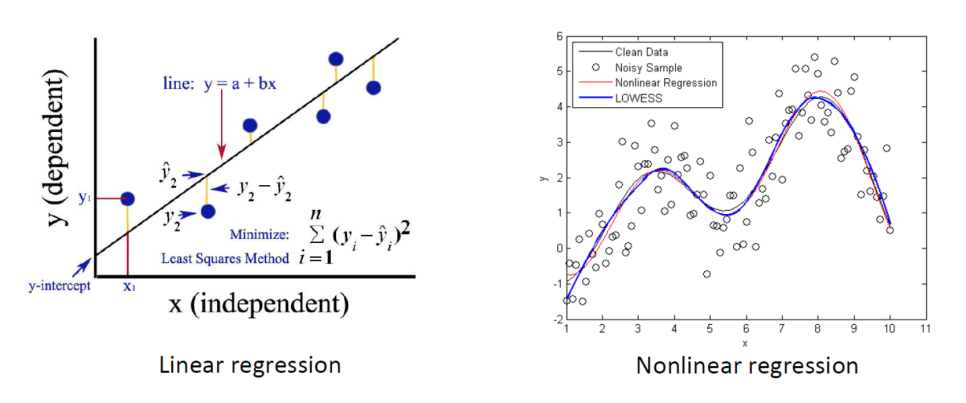
* Linear Regression : 선형 회귀 분석
* Nonlinear Regression : 비선형 회귀 분석
- Classification problem [Discrete]
목적 : 데이터의 클래스를 올바르게 구분하는 선을 찾는 것
여기에서 데이터의 클래스란, 데이터의 '성격'으로 생각하면 쉽다.
[ 예시 1 ] : 영화 장르 구분
영화에서 장르를 구분하는 것처럼 데이터의 성격마다 유사한 데이터끼리 묶어 클래스를 구분할 수 있다.
영화 모가디슈를 '액션' 으로 구분한다면 좌표 상에 적당한 위치에 모가디슈가 존재하게 될 것이다.
모가디슈의 위치를 파악하여 모가디슈를 '액션' 장르로 구분할 수 있는 올바른 선을 찾는 수식을 반영한다.
물론 이때 주어진 다른 데이터의 결과를 최대한 잘 구분하는 선이어야 한다.
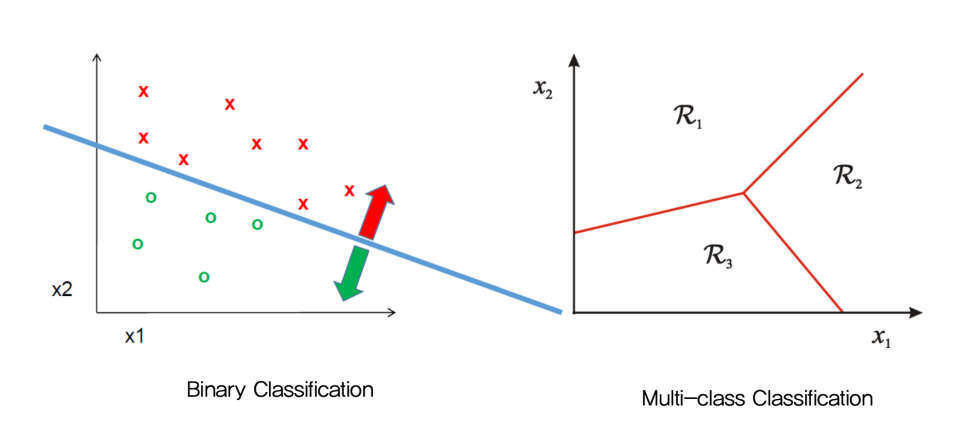
* Binary Classification : 두 가지로 분류.
* Multi-class Classification : 여러 가지로 분류.
Unsupervised Learning
- Clustering Problem [ Continuous ]
목적 : 다수의 샘플을 알아서 그룹을 생성하여 구분하는 것
각 similarity를 비교하여 유사한 샘플을 가까이에 배치하는 것으로 그룹을 나눈다.
이때, similarity를 정하는 기준은 feature로 결정하는데, 이 feature를 결정하는 것은 개발자가 된다.
[ 예시 1 ] : 음악 장르 구분
100곡의 음악이 플레이 리스트에 있을 때, 각 음악이 가지는 특색을 분석하여 유사한 음악끼리 묶는다.
이때, 유사한 음악에 대한 기준은 비트 수, 가사의 유무 등 다양한 기준을 세울 수 있는데, 이것을 feature(특징)이라고 한다.
이 feature는 하나의 '차원'(Dimension)이라고 부를 수 있는데, 차원이 늘어날 수록 계산이 복잡해진다.
따라서, 적절한 feature를 선정하는 것 또한 중요한 과정 중 하나이다.
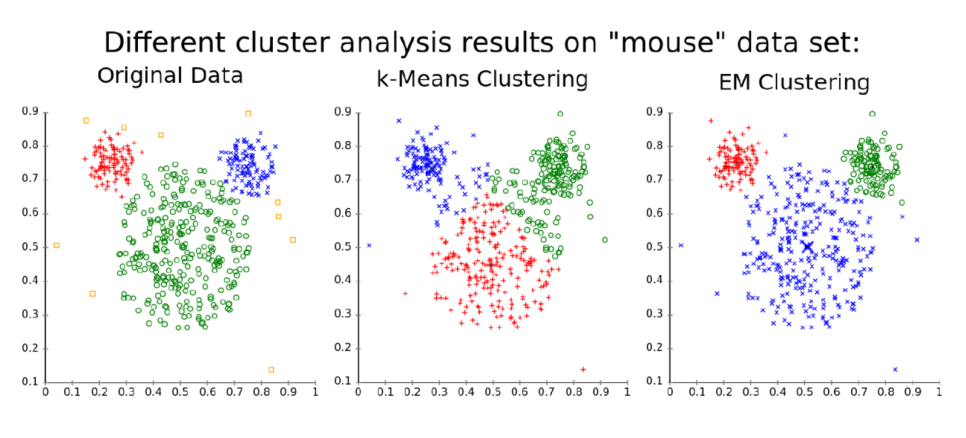
아래의 그림은 k-means clustering 과 EM clustering 이라는 두 가지 머신러닝 테크닉을 이용하여 데이터를 구분해본 모습이다.
k-means 보다 EM이 더 잘 구분되는 모습을 볼 수 있다.
- Dimensionality Reduction problem [Discrete]
목적 : 차원 축소
필요한 feature만 사용하기 위해 중요 feature를 선택하거나 줄이는 기법.
이렇게 feature를 줄이면서 차원을 줄이면 더 효율적으로 계산 과정을 간략화 할 수 있다.
차원을 줄이지 않으면 '차원의 저주'라는 현상이 발생한다.
'차원의 저주'란, 차원이 많아지면 많아질수록 feature가 가지는 특징의 의미가 점점 옅어지는 현상이다.
[ 예시 1 ] : PCA(Dimensionality Reduction)
PCA 란, 데이터의 분산이 커지는 (데이터가 가장 많이 겹쳐서 data loss가 가장 적어지는) 부분을 찾아주는 기법이다.
분산이 커진다는 의미는 데이터의 변화에 따라 결과의 변화량이 커진다는 것을 뜻한다.
따라서, 분산이 큰 feature(특징)은 올바른 결과를 도출하는데 중요한 역할을 하는 것이라고 추측할 수 있다.
다음 그림을 살펴보면 3차원의 공간을 가지는 좌측 그림이 있다.
여기서 PCA 기법을 활용하면 우측의 그림처럼 변화한다.
이 우측의 바둑판은 좌측 그림에서 누운 사각형과 같은 것이다.
따라서, PCA를 통해 3차원을 2차원으로 줄이면서도 각 샘플에 대하여 분산이 높은 지점을 선택하여,
분산의 총 합이 가장 높은 지점에 2차원 공간을 선택하여 과한 정보 누락이 일어나지 않도록 했음을 알 수 있다.

데이터 소실이 가장 적게 일어나는 부분을 선택하여 3차원을 2차원으로 줄이는 모습의 PCA
이런 차원 축소 기법은 다른 알고리즘과도 함께 사용이 된다.
아래의 그림처럼 차원 축소 과정을 거친 뒤, Clustering 이나 Classification, Regression 등의 과정을 진행할 수 있다.
따라서, 차원 축소 과정은 일종의 전처리 단계 (정보를 가공하는 단계)로 분류할 수도 있다.

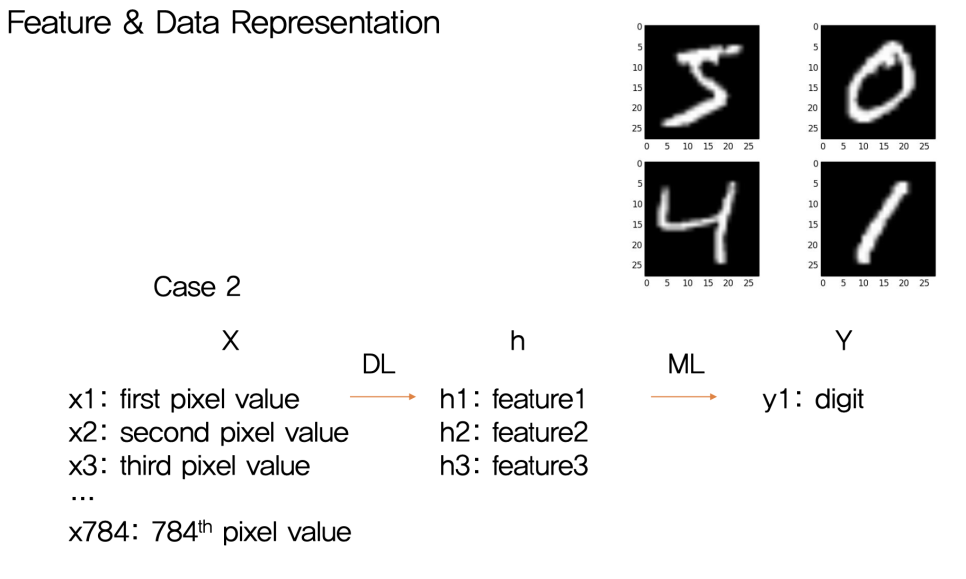
다음 그림은 차원 축소를 이용한 뒤 머신러닝 기법을 활용하여 Y를 도출하는 모습을 나타내고 있다.
Case2 에서 보이는 X는 784개의 pixel value(feature)를 가진다.
이를 3차원으로 줄여 ML(Machine Learning)을 거쳐 y1를 추출한 모습을 볼 수 있다.
훨씬 간단한 계산식을 거쳐 값을 낼 수 있음을 알 수 있다.
예시. 고차원의 데이터를 저차원으로 차원축소를 하여 활용한다.